前言
在系统出现性能瓶颈,要进行性能优化的时候,我们可能会考虑使用如Redis这样的中间件实现缓存来提高系统的性能。当然这个肯定要考虑业务场景,不是所有的业务场景都是可以使用缓存的。本文重点不是引入缓存的时机,也不是缓存架构如何实现,今天只是来说说引入缓存之后带来的缓存穿透、缓存击穿和缓存雪崩这三个问题。
使用缓存时数据访问的流程
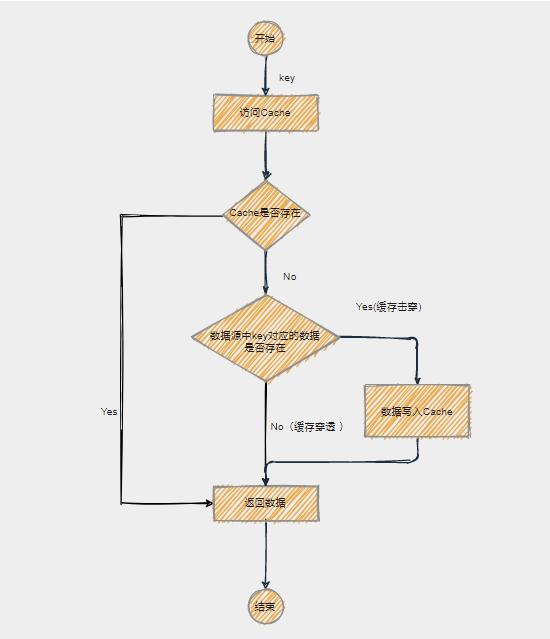
使用cache之后,访问数据的流程就不再像之前那样直接请求数据库,而是先请求cache,cache中没有数据,则再去请求数据库。
缓存穿透
什么是缓存穿透
当请求cache时,cache中对应的缓存不存在,然后去请求数据库,但是数据库中也没有对应的数据。这样的请求每次都无法命中缓存,缓存失去了他的用处。
有什么问题
假设在商品详情页,有人直接改动浏览器上地址,去访问id<=0的商品,id<=0的商品对应的数据无论是在cache还是在数据库中都不会有,那么如果有黑客利用此漏洞进行攻击,则有大可能压垮数据库。
缓存击穿
什么是缓存击穿
当请求cache时,cache中对应的缓存不存在,然后去请求数据库,数据库存在对应的数据。
有什么问题
如有高并发的场景下,在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让数据库崩溃。
缓存雪崩
什么是缓存雪崩
缓存服务器重启或者缓存服务器中的缓存在同一时间失效。缓存击穿关注的是单个缓存key,缓存雪崩关注的是一大批缓存key。
有什么问题
缓存在同一时间失效,这时有高并发的场景,短时间内请求都打到了数据库上,也会压垮数据库。
解决方案
如何解决缓存穿透的问题
解决这个问题,我们可以看看小伙伴在使用缓存的时候代码是怎么写的,伪代码如下:
1 | public Object findDataById(int id){ |
我想小伙伴们差不多都是这么写的,这样写在正常的情况下是没有问题的,但是一旦id是一个小于0数或者id对应的数据在数据库中就是没有,系统在高并发、大流量的情况下,问题就随之而来了。那我们应该如何解决呢?
进行一定的数据校验,其他的直接缓存null
对于商品id来说,这样的数据是肯定是没有小于0的,所以我们可以在方法的入口,增加对应的数据校验,id小于等于0的请求直接拦截。符合校验规则,但是数据库中确实没有的则也直接缓存,但是注意他的缓存时间设置的不会太长,具体时间看大家的业务要求。所以上面的伪代码可以优化如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public Object findDataById(int id){
if (id <= 0) {
throw new RuntimeException("id不合法");
}
Object data = Cache.get(id);
if (data != null) {
return data;
}
int time = 3;
Object data = DB.findById(id);
if (data == null){
time = 1;
}
Cache.set(id,data,time);
return data;
}这样的写法不够优美,不符合单一原则,毕竟只是伪代码,大家凑活着
使用布隆过滤器拦截
利用布隆过滤器(Bloom Filter),它可以使用很小的内存空间内查找某个数据是否存在。我们可以将可能存在的key都保存到bitMap中,根据布隆过滤器的特点,一个数据如果判定为存在的时候,数据不一定存在,但是判定结果为不存在的时候,则数据一定不存在,这样我们就可以过滤那些不存在的key。
对比两种解决方案,我比较倾向于前一种,实现简单,一般场景下也是没有问题的。
如何解决缓存击穿的问题
- key不设置过期时间
我们将数据缓存到Cache中,一般都是会设定过期时间的,那对于发生了缓存击穿(热点)的key来说,我们可不可以不设置过期时间,即key永远不过期,如果数据有变动则直接删除key。
如何发现热点key?这里给出两个简单的方法。1. 根据业务经验预估 2.使用redis自带的命令预估,如monitor命令进行分析或者redis-cli使用hotkeys参数
如果数据有变动则直接删除key,这个要是拿来说一说,也是可以水一篇文章的。
- 使用互斥锁
伪代码如下:
1 | public Object get(key) { |
缓存预热
缓存预热就是系统直接把缓存创建起来,不需要走之前那一套缓存建立的流程。这个方案适用于上架一个商品,业务在后台配置好之后,直接起一个线程处理好这个商品的相关缓存。
如何解决缓存雪崩的问题
缓存雪崩其实是缓存击穿的极端情况。前面说到了发生缓存雪崩的两个场景,一是因为服务发生了宕机导致缓存不可用,二是因为大批缓存的key在短时间内同时失效,所以针对这两种情况,我们可以给出以下的解决方案。
缓存系统的高可用
redis的支持多种高可用的方案,如哨兵模式、Redis Cluster等。
避免热点key的过期时间相同
缓存key在设置过期时间时,在正常的过期时间上加上一个随机时间,这样可以让缓存失效的时间点尽量均匀。
总结
前文说了本文的重点只是探讨缓存穿透、缓存击穿和缓存雪崩三个问题,缓存其他的问题都没有涉猎。再说一次缓存不是提高系统性能的万精油,而且解决上述问题的各种方案也是需要看自己系统情况和业务要求去灵活的运用。大家如有什么疑问或者不同的意见可以提出来我们讨论讨论。