前言
随着业务的发展,系统功能也越来也复杂。渐渐的我们会遇到这样的问题。例如,系统和多个外部系统交互对接耗时耗力、系统某个模块流程处理时间过长业务越来越接受不了、某个模块在某个时间点流量太大系统时刻有宕机的风险等等。对于这些问题要想解决,系统此时引入消息队列或许是一个不错的选择。我们都知道消息队列有三大技能:解耦、异步、削峰。看起来可以完美的解决上面提到的问题,但是你们的系统真的适合消息队列么?
系统在引入消息队列之后到底会带来哪些不好的影响,我们今天来说一说:
系统可用性降低,增加运维难度
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。以前A、B、C三个系统正常,服务就没有问题。现在A系统引入消息队列,B、C消费消息,现在消费队列宕机,业务就执行不下去了。如何保证MQ的高可用?
系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。如何保证消息没有被重复消费?怎么处理消息丢失情况?如何保证顺序消息能被正确的消费?
一致性问题
A系统处理完业务,通过MQ给B、C系统发消息数据,如果B系统、C系统处理失败。这样的情况要怎么处理,如何保证消息数据处理的一致性?
看到了吧引入一个消息队列,就会带来这么的问题!所以大家在使用消息队列的时候,千万要想清楚,自己的系统适不适合、有没有那个运维能力、业务能不能接受!本文这次只谈如何让消息队列不丢失消息,且以RocketMQ为例。

一个消息到开始到结束会经历这么三个阶段:生产阶段、消息队列Broker存储阶段和消费阶段。一个消息在三个阶段中的任何一个阶段都有可能丢失,知道这个之后,我们只要保证这三个阶段不出现问题,消息自然就不会出现丢失了。接下来我们来细说一下如何保证这三个阶段不出现问题。
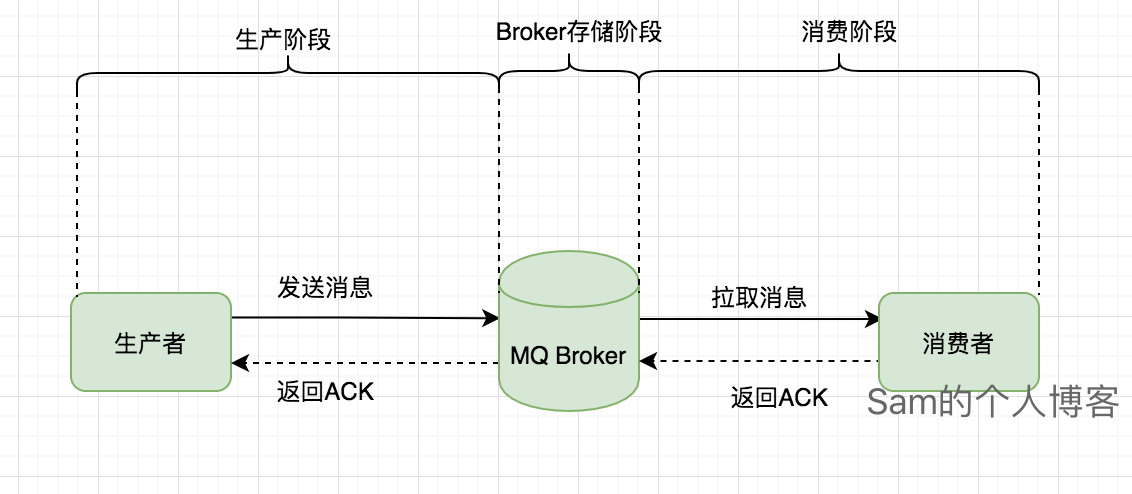
生产阶段
生产阶段的使命就是将消息发送到队列之中。生产者(Producer)通过网络请求将消息发送给消息队列,消息队列接受到之后返回响应给生产者。RocketMQ有两种常用的消息发送方式:同步发送、异步发送。
同步发送
1 | DefaultMQProducer producer = new DefaultMQProducer("unique_group_name", true); |
同步发送时只要send()方法没有抛出异常,就可以认为消息发送成功,即消息队列Broker成功接受到了消息。
既然是同步发送肯定就比较耗费一些时间,如果你的业务比较注重RT那就可以使用异步发送的方式。
异步发送
异步发送消息的方式可以降低消息发送的RT,我比较喜欢这种方式。
1 | DefaultMQProducer producer = new DefaultMQProducer("unique_group_name", true); |
使用异步发送方式时记得重写SendCallback类的两个方法,在onSuccess()方法中更新消息的发送状态为发送成功,只要不发生异常且回调了onSuccess()方法也可以认为成功发送到了Broker。
SendStatus问题
发送消息时,将获得包含SendStatus的SendResult。以下是每个状态的说明列表:
SEND_OK
SEND_OK并不意味着它是可靠的。要确保不会丢失任何消息,还应启用SYNC_MASTER或SYNC_FLUSH。FLUSH_DISK_TIMEOUT
如果Broker设置MessageStoreConfig的FlushDiskType = SYNC_FLUSH(默认为ASYNC_FLUSH),并且Broker没有在MessageStoreConfig的syncFlushTimeout(默认为5秒)内完成刷新磁盘,您将获得此状态。FLUSH_SLAVE_TIMEOUT
如果Broker的角色是SYNC_MASTER(默认为ASYNC_MASTER),并且从属Broker未在MessageStoreConfig的syncFlushTimeout(默认为5秒)内完成与主服务器的同步,则您将获得此状态。SLAVE_NOT_AVAILABLE
如果Broker的角色是SYNC_MASTER(默认为ASYNC_MASTER),但没有配置slave Broker,您将获得此状态。
对于SendStatus有多种情况的问题,因此无论使用同步还是异步的发送方式,都需要判断SendStatus是不是SEND_OK,如果不是则需要针对不同的情况进行分别处理。
FLUSH_DISK_TIMEOUT,FLUSH_SLAVE_TIMEOUT
这两种情况说明消息落盘出现了异常,为了不丢失消息,我们可以稍等时间后重发消息。SLAVE_NOT_AVAILABLE
这种情况说明集群中的Slave不可用,重新发送是无用的,需要人工介入处理。
其实你查看RocketMQ的源码就会发现,不论是同步发送还是异步发送,都是可以针对不同的场景自定义重试次数的,而且很多方法还有内部重试机制。
Warn: this method has internal retry-mechanism, that is, internal implementation will retry
{@link #retryTimesWhenSendFailed} times before claiming failure. As a result, multiple messages may potentially
delivered to broker(s). It’s up to the application developers to resolve potential duplication issue.
源码默认的处理方式
1 | /** |
自定义重试机制:
1 | producer.setRetryTimesWhenSendFailed(5); |
这里就要提下消息投递语义(message delivery semantic),简单的来说就是消息传递过程中的传递保证。主要分为三种:
- at most once:最多一次。消息可能丢失也可能被处理,但最多只会被处理一次。
- at least once:至少一次。消息不会丢失,但可能被处理多次,可能重复,不会丢失。
- exactly once:精确传递一次。消息被处理且只会被处理一次,不丢失不重复就一次。
有些异常情况的出现,可能是因为网络的偶尔波动导致,其实已经发送到了Broker,只不过是返回ACK给生产者的时候出现了超时,这个时候生产者重试就会导致消息重复投递。毕竟生产者为了保证消息一定成功投递到Broker中,就无法保证只进行一次精确投递。为了防止消息重复消费,那就需要消费者自身保证业务处理的幂等性。另外对于发送状态SendStatus 不是SEND_OK的消息要使用定时任务进行补偿发送。还要提到一点的就是,重试也是需要做好限制的,设定最大重试次数,也要保证重试的时间间隔,毕竟经验告诉我们,有些异常情况下短时间内的重试是没有意义的。具体的设计可以参考我之前文章中的本地消息表方案,本地事务+定时任务补偿保证消息一定投递成功。
消息队列Broker存储阶段
默认的情况下,消息队列为了快速响应,在接受到生产者的请求,将消息保存在内存成功之后,就会立刻返回ACK响应给生产者。
你以为人家的架构是这样的:
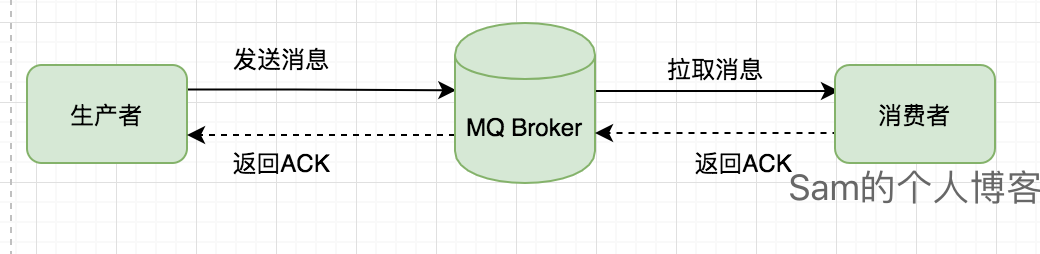
消息刷盘方式
同步刷盘
在返回写成功状态时,消息已经被写入磁盘。具体流程是,消息写入内存的PAGECACHE后,立刻通知刷盘线程刷盘, 然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写 成功的状态。异步刷盘
在返回写成功状态时,消息可能只是被写入了内存的PAGECACHE,写操作的返回快,吞吐量大;当内存里的消息量积累到一定程度时,统一触发写磁盘动作,快速写入。
将默认的异步刷盘修改成同步刷盘
1 | flushDiskType=SYNC_FLUSH |
异步刷盘方式在遇到消息队列宕机、机器异常断电或者内存硬盘损坏的情况,消息就无法成功持久化到硬盘中,那这个消息就永久丢失了。对于这种情况,我们就需要改变RocketMQ的刷盘机制,将默认的异步刷盘,修改成同步刷盘。即消息成功保存到硬盘上时才返回给生产者ACK响应。
其实人家的架构是这样的:
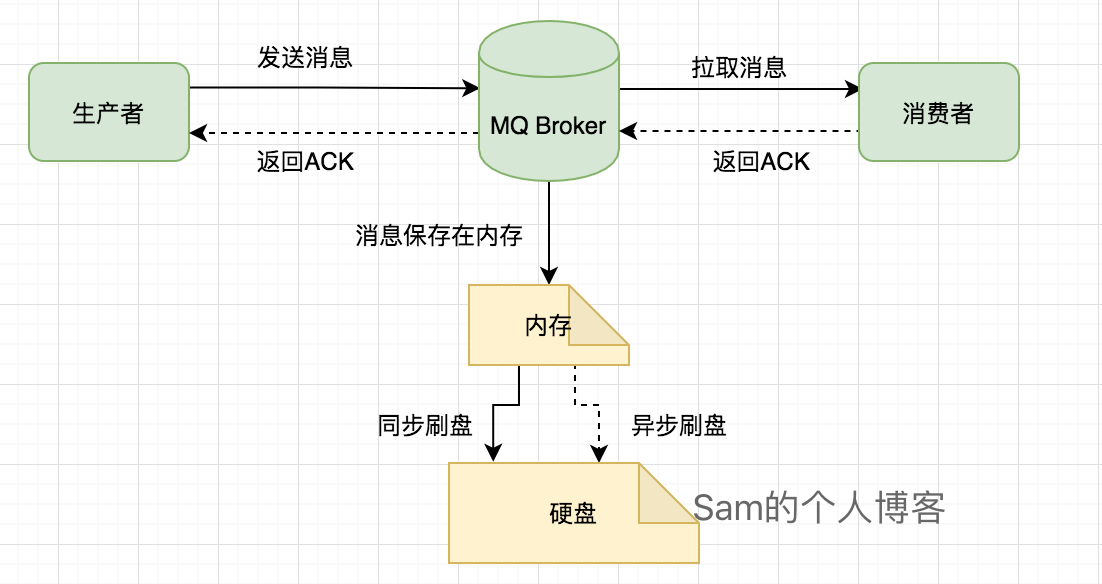
同步刷盘的缺点很明显,那就是降低了吞吐量,加大了消息发送的响应RT时间,但是为了不丢失宝贵的消息这一点损耗是值得的。
集群部署
上面讲的是单个消息队列Broker对于可靠保存消息的处理方式,但是生产环境肯定是采用的集群部署。目前RocketMQ支持单Master模式、多Master模式、多Master多Slave模式(异步)和多Master多Slave模式(同步)4种集群方式。
我这里申明一下,生产环境下的消息队列一定是采用集群的方式进行部署,不会有单机部署的情况。自己在本地搞搞单机部署玩玩肯定是可以的,生产环境也这么搞,你肯定是在逗我!
单Master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试。
多Master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:
- 优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
- 缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
多Master多Slave模式
异步刷盘多Master多Slave模式
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
- 缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
同步多Master多Slave模式
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
- 优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
- 缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
即使消息成功保存到了Master的硬盘上,然后在Master将消息同步给Slave的时候,这个期间Master挂了,而且是那种硬盘修不好的那种,不要说这种情况不可能,支付宝的专用电缆都能被挖断,还有啥不可能的。哈哈哈,也是够倒霉的!
其实人家真正的架构是这样的:
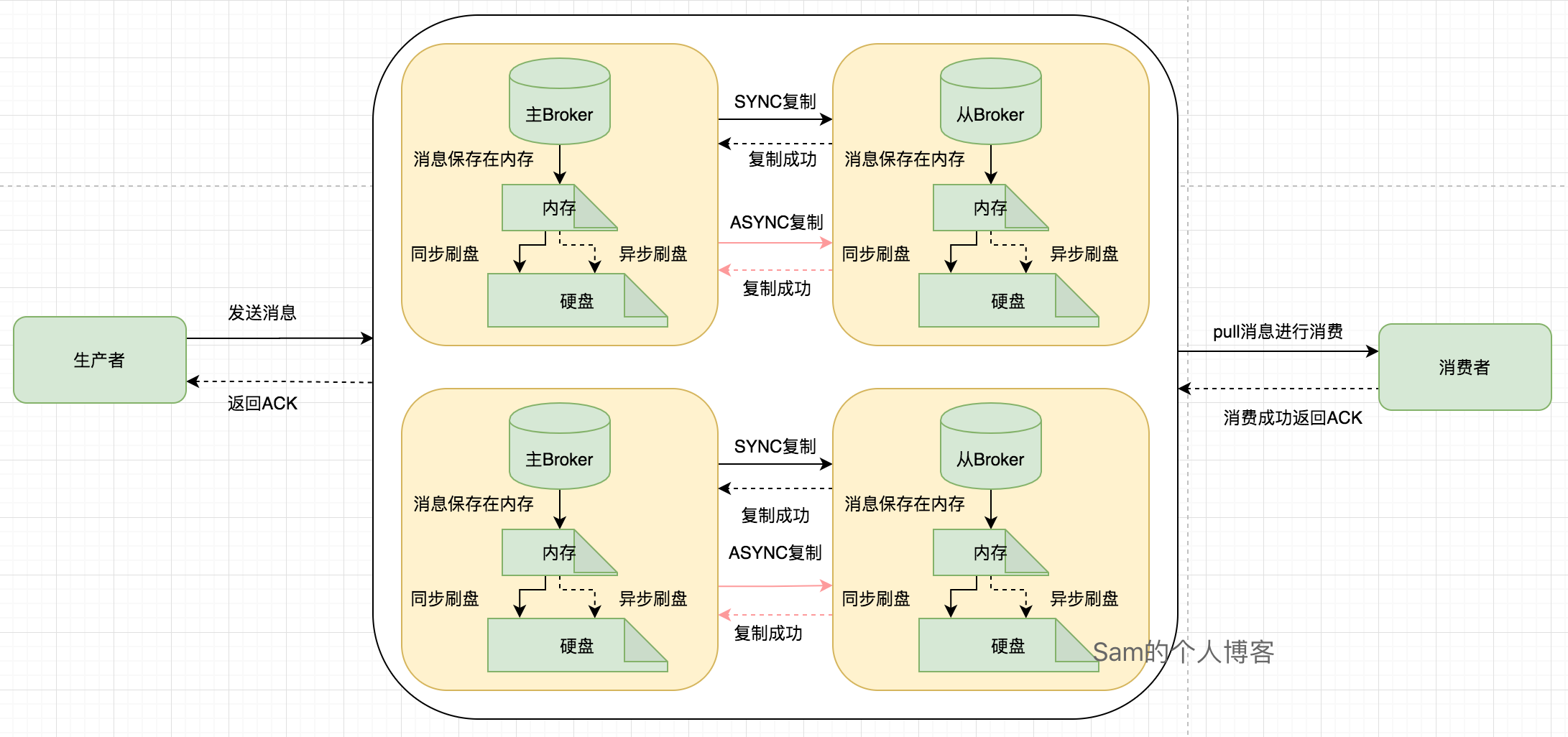
四种集群方式优缺点都列出来了,很明显为了保证消息一定不会在Broker这个阶段丢失,生产环境一定要使用第四种集群方式:同步复制多Master多Slave模式。具体配置如下:
1 | ## master 节点配置 |
加上前面的同步刷盘的配置,这样生产者发送消息给Broker,Master使用同步刷盘方式将消息保存到硬盘上,保存成功之后使用同步复制的方式将消息复制到Slave上,slave保存成功之后,Broker才返回给生产者ACK。
消息堆积
对于并发比较高的系统,如果下游的消费者宕机,则会导致大量的消息堆积在消息队列里,这样很容易会把服务器的硬盘撑爆,新的消息发送到消息队列,硬盘拒绝写入,这时消息很容易就会丢失。所以,部署消息队列的机器硬盘空间要比较充裕,且要有一定的监控,防止这种情况发生。
消费阶段
终于到了最后一个阶段,但是大家也不能大意。消费者拉取消息进行本地业务处理,业务处理完成才能提交ACK ConsumeConcurrentlyStatus.CONSUME_SUCCESS,切不可先提交ACK再进行业务处理。如果业务处理出现异常情况,可以先返回ConsumeConcurrentlyStatus.RECONSUME_LATER等待消息队列的下次重试。
1 |
|
还有一点要注意的是,消息队列 RocketMQ 默认允许每条消息最多重试 16 次,每次重试的间隔时间如下:
| 第几次重试 | 与上次重试的间隔时间 | 第几次重试 | 与上次重试的间隔时间 |
|---|---|---|---|
| 1 | 10 秒 | 9 | 7 分钟 |
| 2 | 30 秒 | 10 | 8 分钟 |
| 3 | 1 分钟 | 11 | 9 分钟 |
| 4 | 2 分钟 | 12 | 10 分钟 |
| 5 | 3 分钟 | 13 | 20 分钟 |
| 6 | 4 分钟 | 14 | 30 分钟 |
| 7 | 5 分钟 | 15 | 1 小时 |
| 8 | 6 分钟 | 16 | 2 小时 |
如果消息重试 16 次后仍然失败,消息将不再投递。如果严格按照上述重试时间间隔计算,某条消息在一直消费失败的前提下,将会在接下来的 4 小时 46 分钟之内进行 16 次重试,超过这个时间范围消息将不再重试投递。此时,消息队列 RocketMQ 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。在消息队列 RocketMQ 中,这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。死信队列里的消息有效期与正常消息相同,均为3天。3天后会被自动删除。针对这种情况,为了不丢失消息我们需要处理死信队列里的消息。
有消息进入死信队列,意味着某些问题导致消费者无法正常消费消息,因此,通常需要人工介入对其进行特殊处理。排查可疑因素并解决问题后,可以在消息队列 RocketMQ 控制台重新发送该消息让消费者重新消费一次,或者直接让专门的消费者订阅死信队列进行消费。
死信队列名称一般是 %DLQ% + ConsumerGroupName组成,还有个重试队列名称一般是 %RETRY% + ConsumerGroupName组成,这些都是RocketMQ自动创建的。
总结
一个消息从新生到终结经历了生产、存储、消费三个阶段,针对不同的阶段可能会出现丢失消息的地方,我们给出不同的解决方案。最终,RocketMQ丢失消息的概率被大大的降低了。我们将视角拔高一点,你就会发现,解决不同的消息队列不丢失消息,只有消息队列的配置稍有不同,其他地方都是类似的。好像我们已经形成了解决消息不丢失的方法论了,再遇到其他的消息队列我们就不慌了。